Project / 01
SPIKE - NASA research explorer
NASA Space Apps 2025 prototype for exploring 607 space-biology publications. Built by a six-person team, it combines PMC metadata, tag filtering, timeline and subject-tree views, and a Flask/OpenAI summarizer.
The problem
Space-biology research is spread across long academic papers, metadata tables, and subject tags that are useful only after you already know what to search for. For NASA Space Apps 2025, the interesting problem was not building another text box. It was turning a corpus of space-related publications into something a researcher could scan, filter, and summarize quickly.
SPIKE does that by combining a static publication dataset with live article summarization. The app lets a user browse 607 PMC-linked papers, narrow them by title, PMID, date, and subject tags, switch between table, timeline, and subject-tree views, then request an AI summary for a selected paper.
My role
On a six-person team, I mainly worked on the backend and AI layer: the Flask summary endpoint, article downloader, HTML section extraction, prompt construction, and OpenAI response contract for summaries, key findings, limitations, and future directions.
I also contributed to the frontend where the research experience needed motion and feedback, including the summary speed slider and the animated globe scene. That gave the prototype a stronger first impression while keeping the core work focused on the research pipeline.
System design
SPIKE splits into a fast path and a slow path. Static JSON drives the dashboard and its table, timeline, and subject-tree views with no server; selecting a paper triggers the slower live path - Flask extracts the article and calls OpenAI for a structured summary.
The frontend is a Next.js app built with Material UI. It loads publication, tag, summary, and subject-tree JSON files directly into React components, which keeps the browse experience fast and avoids needing a database during the prototype window.
The backend is a small Flask service. A selected title hits /get_summary/<title>, downloads the matching PMC article HTML, extracts article sections with BeautifulSoup, builds a constrained prompt, and asks OpenAI for strict JSON with summary, key_findings, limitations, and future_directions. I owned this backend and AI flow during the prototype.
Key technical decisions
- Static JSON for the browse path. The project ships the 607-publication dataset, 99 tag options, and subject-tree artifact as local JSON. That made the main UI reliable even while the AI path was still being wired up.
- One data shape across views. The same filtered publication rows drive the table, timeline, and subject tree. That kept filtering behavior consistent and made the visualization modes feel connected instead of separate demos.
- Section extraction before LLM calls. The summarizer does not send raw page HTML to the model. It extracts relevant article sections first, which reduces prompt noise and keeps the summary prompt focused.
- Structured output prompt. The AI prompt asks for strict JSON with a small schema. The next step is server-side validation, but the prototype already established the response contract the UI expects.
Results
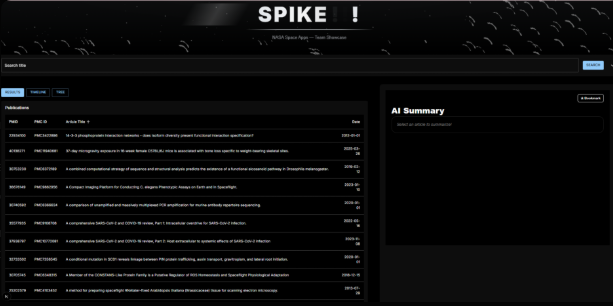
The main dashboard: searchable publication table on the left, AI summary panel on the right, and view controls for results, timeline, and subject tree.
The globe scene gave the prototype a stronger space-research identity and made the demo feel less like a plain data table.
The repo contains a working NASA Space Apps 2025 prototype shape: searchable and paginated publication browsing, advanced filters for title, link, PMID, date, included tags, excluded tags, and AND/OR tag logic, plus timeline and subject-tree views over the same corpus.
The data artifacts are concrete enough to talk about: 607 publication records, 99 unique tag options, a 166-node subject tree, and a first 40-row summary subset for the frontend. The AI summary panel includes loading/error states, a typewriter-style summary display, speed control, bookmark affordance, JSON download support, and a direct "Open Article" link. I also helped with the globe visualization that gives the page its space-research feel.
What I would do differently
I would replace the title-in-path summary endpoint with a POST endpoint that accepts a PMC ID. A long academic title in a URL is fragile, and PMC ID is already present in the dataset.
I would also make the extraction pipeline article-safe. The current backend writes to shared temporary files like raw_temparticle.html and extracted_temparticle.json, which is fine for a local demo but not safe for concurrent requests. A per-PMC cache would make the system easier to debug and faster after the first request.
Finally, I would harden the AI boundary before presenting this as more than a prototype: validate model JSON on the server, treat article text as untrusted input, add clearer failure states for malformed responses, and remove hardcoded local URLs between the frontend and Flask service.